We often think of a token in the transformer architecture of LLM's as being associated with a vector in a high dimensional euclidean space $\mathbb{R}^d$, but there is an exciting new area of research called Geometric Deep Learning[1] which is based on studying the topology of the "manifold" or the "latent space" where we imagine these vectors to be points on a surface rather than points in a purely Euclidean space.
An exciting new frontier in geometric deep learning is the concept of a Sheaf Neural Network[2]. In this blog post I'd like to explain the meaning of the word "Sheaf"[3] using developer friendly language, and explain my new project StreamAlign and how we can use the sheaf framework to understand existing models such as gpt-2.
The default input in the demo is "The moon is made of green cheese. The moon is made of rock. The moon is made of spaghetti." This is the context window.
Each word in the context window is associated with a token which is indexed by its position in the sequence, each token is associated with a point in $\mathbb{R}^d$, and for each token there is a hidden state vector $h_i$ associated with the token at position $i$. For a given context window, we can form the collection of all $h_i$.
If you understand that then you already are in a position to understand the language of sheaves. In this case, the context window is whats called the Base Space and we can imagine that associated with each token there is a vector space $\mathbb{R}^d$, and a token is associated with a vector in this space. In the language of Sheaves, the space $\mathbb{R}^d$ is called the Stalk and the hidden vector $h_i$ is called the Germ. The collection of all $h_i$ (for a given context window) is called the Section.
We are now in a position to understand the following statement:
The transformer architecture can be modelled as a Sheaf ${\cal S}$ over the base space ${\cal B}$ where ${\cal B}$ is the context window.
In the transformer architecture, the attention mechanism is used to compute a kind of projection between the Query matrix ($Q$) and the Key matrix ($K$), but we have to be really careful to separate out two distinct concepts. On the one hand, when we transport a vector along a surface we have the concept of parallel transport or in geometry whats called the Connection; but when we transport vectors along a manifold with a given topology, we have to compute the cost associated with that transport. An optimal transport problem in this context is the problem of determining the minimum cost to transport a vector from one position to another.
The transformer projects the hidden states $h_i$ into a shared interaction space (the attention head) to produce $Q$ and $K$, the agreement between these projections corresponds to the connection (or parallel transport), in the language of sheaves the projection matrices $W_Q$, $W_K$ function as the Restriction Map. The attention matrix $A_{ij}$ defines the weighted topology of the manifold.
To understand how we can apply these insights to intrinsic methods of detecting hallucinations in LLM, we need to understand one more concept: Cohomology. We can understand cohomology as a kind of "hole" in the manifold or a "topological obstruction", these topological obstructions are indications of hallucinations where the local structure is logically consistent but the global structure is not logically consistent.
For example consider the following context window:
Agent A trusts Agent B.
Agent B trusts Agent C.
Agent C distrusts Agent A.
In the sheaf framework this represents what is called a "non-trivial cohomology". This is quite different from how we understand this context window if we only think in terms of vector embeddings. This is the advantage of the Sheaf framework.
The Dirichlet Energy
The main observable we are measuring in the live demo is the Dirichlet Energy. Now that we understand the concepts which map sheaf theory to the transformer architecture, there is one final piece of the puzzle: we need the expression for the spherical Dirichlet energy ${\cal E}$ of the attention mechanism $A_{ij}$.
$${\cal E}_i = \sum_j{A_{ij}\|Q_i - K_j\|^2}$$
A harmonic section occurs when the total energy is minimized, this is a state where information flows freely without resistance, it corresponds to the harmonic component of the H0 cohomology group. A topological obstruction is a state which causes irreducible internal stress and is related to the H1 cohomology group.
To understand this, we can directly reference the StreamAlign codebase. In core/sheaf.py we have the following lines:
# Instead of directly comparing hidden states $h_in$
# we project them onto the Query/Key space.
Q = h_in @ W_Q
K = h_in @ W_K
$W_Q h_i$ is the "local data" at node $i$ viewed in the edge space. $W_K h_j$ is the data at node $j$ transported to that same space. If they align, the connection is "consistent."
In core/geometry.py we are projecting everything onto a unit hypersphere.
# 1. Spherical Projection
# We normalize to remove magnitude (confidence) and keep only direction (semantics).
Q_norm = F.normalize(Q, p=2, dim=-1)
K_norm = F.normalize(K, p=2, dim=-1)
The Dirichlet energy is computed in the following lines of code
`squared_distance` is the term $\| h_i - P_{ij} h_j \|^2$ in the Dirichlet energy derived from the Sheaf Laplacian. Unlike a standard graph Laplacian, the sheaf Laplacian involves the restriction map $P_{ij}$ corresponding to the process of parallel transport.
The Truth Score
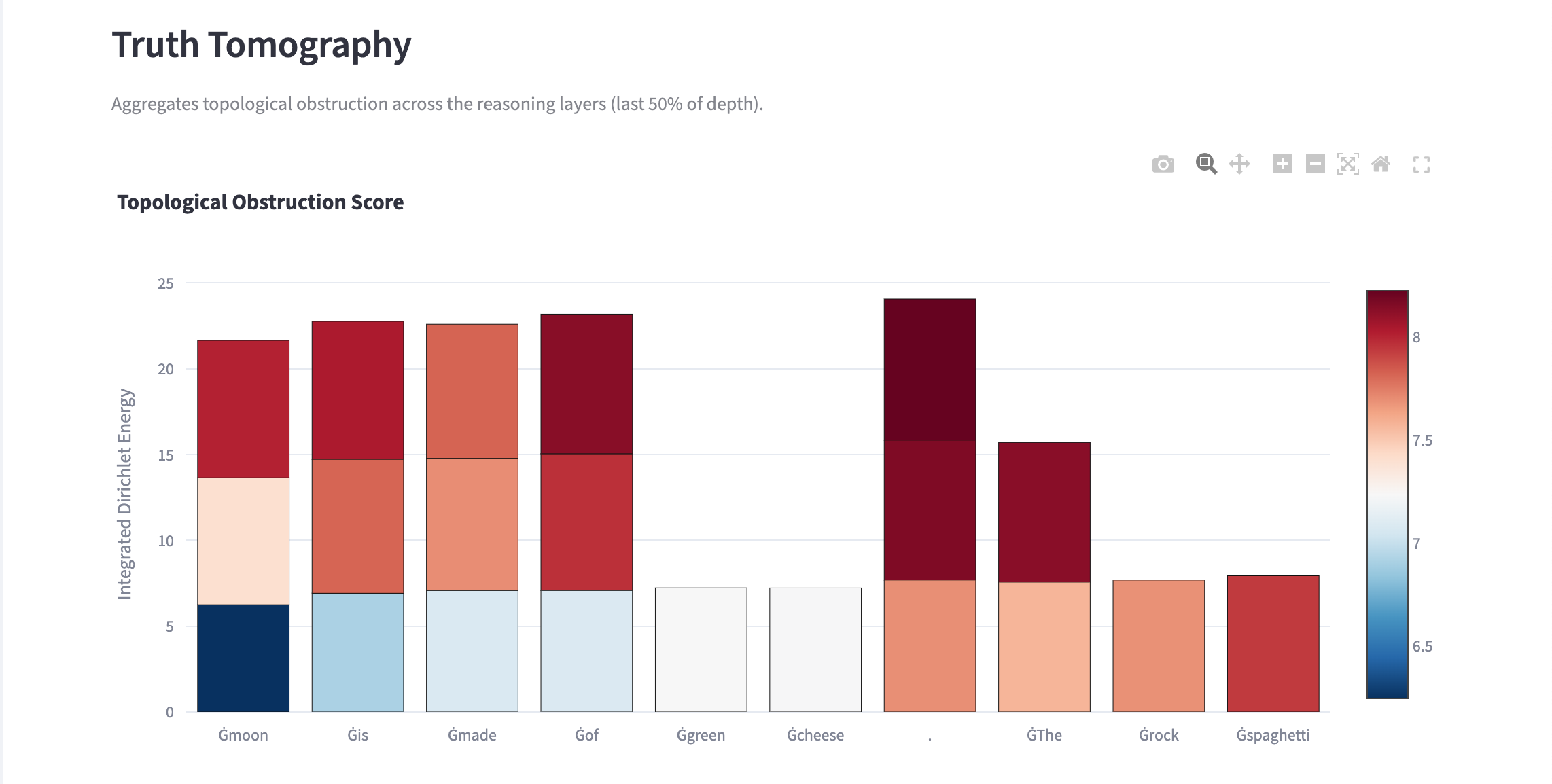
When reviewing the results of this numerical experiment, a suprising finding is that gpt-2 does not significantly distinguish the truth value between "the moon is made of green cheese" and "the moon is made of rock". But the measurements show high stress for the word "spaghetti", as you can see in the image below.
We isolate the later layers in this experiment because the primary semantic processing appears to occur in only about half the layers
The reason for this is the model has frequently seen ("moon")->("green cheese") in its training data because its a common expression. This shows low stress indicates familiarity but not necessarily truth. In a certain sense, the model is using all almost of its energy to conform to the grammatical structure of the sentence "the moon is made of ..." and the gpt-2 model is not powerful enough to effectively distinguish between "green cheese" and "rock"
The data shows that the semantic stress is high on tokens for connecting words like "of", the explanation is that these connecting words tie different parts of the sentence together, and the model must expend a lot of energy when evaluating such a word for this reason.
Even though the data shows higher stress for the word "of" than for "spaghetti", the relative stress of "spaghetti" is much higher than for either "green cheese" or "rock".
Conclusion and Next Steps
The difference between this approach and traditional Sheaf Neural Networks is that we are using the theory of sheaves to directly analyze the behavior of an existing model. The conclusion that seems inevitable (to me) is that the training process for gpt-2 naturally produced a model which effectively is already a type of sheaf neural network.
There are many new directions I am planning to go with this project, including methods to improve the output quality of existing models by measuring the internal stress during inference. This could improve the output quality of existing models without training a sheaf neural network from scratch.
The original motivation for this research, and the direction I am planning to take, is to actually find a way to encourage an LLM to have "good hallucinations" (thoughts which are globally logically consistent); or in other words, to construct a method to evaluate if a given hallucination is a "good hypothesis". This will be important as we continue adapt AI systems to do scientific research in fields where verification is expensive, such as engineering and physics.